Make ODIN APM Settings
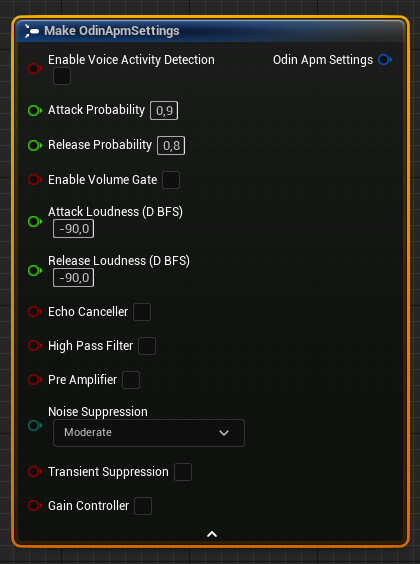
Creates an APM settings object that can be used to construct a local room handle.
Inputs
| Name | Type | Description |
|---|---|---|
| Enable Voice Activity Detection | boolean | When enabled, ODIN will analyze the audio input signal using smart voice detection algorithm to determine the presence of speech. You can define both the probability required to start and stop transmitting. |
| Attack Probability | float | Voice probability value when the VAD should engage. |
| Release Probability | float | Voice probability value when the VAD should disengage. It’s recommended to keep this value 0.1 lower than the attack probability. |
| Enable Volume Gate | boolean | When enabled, the volume gate will measure the volume of the input audio signal, thus deciding when a user is speaking loud enough to transmit voice data. You can define both the root mean square power (dBFS) for when the gate should engage and disengage. |
| Attack Loudness (D BFS) | float | Root mean square power (dBFS) when the volume gate should engage. |
| Release Loudness (D BFS) | float | Root mean square power (dBFS) when the volume gate should disengage. It’s recommended to keep this value 10 lower than the attack loudness. |
| Echo Canceller | boolean | When enabled, aligns the original and the reverse audio stream to negate the output inside the input, resulting in effective echo cancellation |
| High Pass Filter | boolean | When enabled, the high-pass filter will remove low-frequency content from the input audio signal, thus making it sound cleaner and more focused. |
| Pre Amplifier | boolean | When enabled, the preamplifier will boost the signal of sensitive microphones by taking really weak audio signals and making them louder. |
| Noise Suppression | enum | When enabled, the noise suppressor will remove distracting background noise from the input audio signal. You can control the aggressiveness of the suppression. Increasing the level will reduce the noise level at the expense of a higher speech distortion. |
| Transient Suppression | boolean | When enabled, the transient suppressor will try to detect and attenuate keyboard clicks. |
| Gain Controller | boolean | When enabled, the gain controller will automatically bring the signal to an appropriate range. This means input signals with low volume will be amplified and high volume will be limited. |
Outputs
| Name | Type | Description |
|---|---|---|
| Return Value | APMSettings | The constructed APM settings object. |
Discussion
Audio settings can sometimes be challenging to navigate, especially for those new to the field. While many options are straightforward, some require specific values to optimize performance.
In environments with high background noise, it’s essential to prevent this noise from being transmitted. To address this, we offer two key settings:
Voice Activity Detection
Our system utilizes a few milliseconds of audio to ascertain if the user is speaking by leveraging an advanced AI model. It’s recommended to keep this feature enabled.
The AI model operates on a probability scale ranging from 0.0 to 1.0, where 0.0 indicates zero likelihood of voice presence, and 1.0 signifies absolute certainty. Adjust the Attack and Release settings to define the probability thresholds for starting and stopping transmission.
Optimal settings are generally 0.9 for Attack (90% certainty of voice) and 0.8 for Release. We recommend setting the Release value slightly lower than the Attack value, ideally maintaining an offset of 0.1.
While effective in many scenarios, certain situations, like a bustling open-office, may require additional measures. In these cases, the AI might confidently detect voice, but it may not be the voice of the intended speaker.
Here, the Volume Gate filter proves useful:
Volume Gate
The Volume Gate operates by setting a volume threshold below which the microphone remains disabled. This helps distinguish between actual speech and lower-volume background noises. The gate activates only when the detected sound exceeds this threshold.
Understanding this concept might be initially complex. A useful resource is Wikipedia on DBFS.
It’s generally advisable to disable this feature initially. A starting points for settings could be -40 for Release and -30 for Attack. We recommend setting the Release value slightly lower than the Attack value, ideally maintaining an offset of 10. For further assistance, please feel free to contact our support team.